Resource allocation, multiprogramming and scheduling
CPUs can carry out instructions very quickly although it is important to recognise that they can only ever work on one task, or process, at a time. Consider a multi-user network where there are many users on 'dumb' workstations with one central file server (which has one CPU), or consider a single-user system (such as a home PC) where the user is multi-tasking. Each different job or application in use will regularly need some CPU time. But how is the CPU time to be organised, given that it can only do one thing at a time? The organisation of CPU time is another responsibility of the operating system and more specifically, a piece of software within the operating system known as the ‘scheduler’. A computer that is capable of working on more than one application at apparently the same time is also known as a multiprogramming environment.
Scheduling
Scheduling is the name given to the process of managing CPU time. The aims of scheduling are to:
- Make sure the CPU is working as hard and as efficiently as possible.
- Make sure the resources such as printing are used as efficiently as possible.
- Ensure that users on a network think they are the only ones on the system.
How does scheduling work?
A system will have many jobs (which we should more properly call ‘processes’) that need CPU time. For example, in a multi-user environment, one user may need to print a document, another may need to read a file of data, another may need to do a series of calculations, and so on. Each job (or ‘process’) needs some CPU time. In addition, each process may require some input or output from a peripheral such as a printer. Processes that require lots of processor time and very little input/output are known as ‘processor-bound’ jobs. This might be a process, for example, that requires lots of calculations. A process that requires lots of input/output but very little actual CPU processing is known as an ‘I/O-bound’ job. An example would be a process that needs to print a document or needs to read a lot of data from a file. Each process can be classified as a processor-bound job or an I/O-bound job and this is important because the scheduler looks at what resources are available when deciding what process will get CPU time.
Q1. One possible method of organising CPU time is to have a rule: "When the scheduler gets a job, put it into a queue. Process the first job in the queue using the CPU until it is complete. Then get the next job in the queue and give it to the CPU until it is complete, and so on until all processes are complete". This is known as the first-come-first-served scheduling algorithm. What problems can you foresee with this way of organising CPU time?
The scheduler software, then, is responsible for looking at what resources are available (CPU time and peripheral devices), seeing what processes need to be serviced along with what resources they need and then making decisions about what order to put all the processes in, when to start any particular process, and when to finish it. The scheduler software can be broken down into three parts, the high-level, medium-level and the low-level scheduler.
The high-level scheduler (HLS)
The high-level scheduler is responsible for organising all of the processes that need servicing into an order. As each job enters the system, the high-level scheduler places it in the right place in a queue known as the READY TO PROCESS queue. The actual order is based on a ‘scheduling algorithm’ – in other words, some rules about how to order the processes. Some different scheduling algorithms are discussed later in this section. So the high-level scheduler puts new processes in the READY TO PROCESS queue into the primary memory if it can.
The medium-level scheduler (MLS)
If a process is in the RUNNING state (it is in the middle of being serviced by the CPU) and it suddenly needs some peripheral device usage, it is taken out of the RUNNING state and put into the BLOCKED queue. If that process stayed in the running state while waiting for I/O, the CPU would be sitting around wasting time, which isn’t an efficient use of the CPU! A process put into the blocked state can be moved out of the IAS and into backing storage if necessary, to free up memory. When the resources are available to service a process held in the backing store, it can be moved back into the IAS. It is the job of the medium-level scheduler to move a process into and out of IAS as necessary.
The low-level scheduler (LLS)
Once the processes are in the IAS, the low-level scheduler takes control. This piece of software is responsible for actually selecting and running a process. It looks at the order the high-level scheduler has put the processes in by looking at the READY TO PROCESS queue. It then checks that any necessary resources are available for the most important process in the queue and then runs it using the CPU - it takes the process from the READY TO PROCESS queue and puts it into the RUNNING state. It will stay in the running state until either an interrupt happens, that process finishes or the process needs resources that are unavailable, for example, a printer. The low-level scheduler will select the next most appropriate process to give to the CPU. You can summarise what happens with the following diagram.

There are many algorithms that the scheduler can use to put the processes that need servicing into an order. Two of the most common ones are Round Robin (also known as time-slicing) and Priorities. These are discussed next.
A Typical problem
Consider a small network with some workstations and some resources. The network has a server. The server has a CPU. This has to service a number of workstations as well as all of the peripherals. We can represent this with the following diagram.
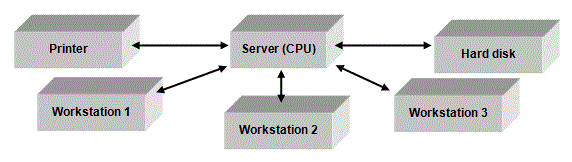
Scheduling ensures the CPU is working as hard as possible.
Consider the above example. Someone working at the first computer is typing in a letter. Even someone typing in at 100 words a minute is only working at a tiny percentage of the processor's speed. Suppose Workstation 2 needs to read a file from the hard drive. Again, this takes a long time compared to the operating speed of the processor. Perhaps workstation 3 is sending an email and requires some I/O to the modem. Even though there are three users on the system they all think that they have sole access to the network because that is what it appears as to them. But they haven't got sole use of the CPU and the associated resources. It's just that the system is scheduling the workload efficiently.
The Round Robin (time-slicing) system
The scheduler looks at the different programs from the different workstations. It puts them all in a queue. It then allocates each item in the queue a slice of CPU time. For example, it might allocate 1/100th second to each item. It then creates a
time-initiated interrupt set for this time interval. Every 1/100th of a second, an interrupt is sent to the processor that tells the low-level scheduler to transfer control from the current program to the next program in the queue. The current program is sent to the back of the queue. Of course, at any time, another interrupt may happen that needs servicing or the process may finish.
From the discussions so far, you should know that a CPU would potentially be executing lots of different programs at 'the same time'. It will try to hold as much of all the programs as possible in primary memory but may need to use virtual memory if enough RAM isn't available. If two users are using the same program, for example, Word 2000, it will only keep one copy in RAM and simply swap information about each job that needs the program into and out of itself as each user is given a CPU time-slice.
The priorities system
Time-slicing isn't the only way that processes can be dealt with by the CPU. Processes can be given priorities and the scheduler can organise processes according to those priorities. For example, some jobs may be submitted in batch mode. These might be run at a time when the resources aren't being used such as at night. They could, however, be submitted in a multi-user environment at any time. In this case, batch jobs would be given a low priority, to be run in the background using the CPU and resources when they aren't being used to do more important jobs. Supervisory programs would be given the highest priority. It is also possible for users to be given priorities, so that one person's work is more important than another person's.
Other algorithms
There are a number of other algorithms that a scheduler might use. For example, jobs might be organised on a first-come-first-served basis. They could be organised on a ‘Do the job that will be finished the quickest’ basis.
Scheduling processes and the Process Control Block
When the CPU stops working on the current process, ready to start working on another program, it needs to record exactly where it is in the current process. This will enable it to pick up from where it left off next time it works on that process. How does it do that? Each program that could run (known as a process, as we’ve already discussed) is allocated a block of memory called a process control block. This will hold the following information:
- Process Identity Number.
- Current state of the job when the job was last left.
- The contents of each register when the job was last left.
- What priority the process has.
- Estimated time for the job to be finished.
- It's current status, whether it is waiting for I/O, whether it's waiting to use the CPU.
- Pointers pointing to areas in memory reserved for this process and resources that could be used.
When a process is stopped, the above details are loaded into the Process Control Block, ready for next time the process uses CPU time. When that time comes, the contents of the PCB are moved into the CPU and the process repeats itself!
Q2. Describe the difference between a ‘processor-bound’ job and an ‘I/O-bound’ job.
Q3. Briefly outline what a scheduler does by breaking down and discussing the three parts to the scheduler software.
Q4. How many jobs can be in the ‘running’ state at any time?
Q5. What is a ‘blocked’ process?
Q6. What 3 circumstances might cause a job to be taken out of the ‘running state?
Q7. What are the aims of scheduling?
Q8. Describe any differences between the round robin and the priorities methods of scheduling.
Q9. Outline two scheduling algorithms, apart from the round robin system and the priorities system.
Q10. Describe the role of the process control block in scheduling.
|
